Cell, the functional unit of life, stores codes of its functioning in long strings called DNA, which is made of different combinations of four chemicals, namely A, G, C, and T. Specific stretches of DNA are called genes or coding regions, and thus a cell contains many genes. These genes code specifically to make proteins through a messenger entity called mRNA, which decodes the code. The proteins take birth at ribosomes inside the cell as a string where each bead represents one amino acid selected out of 20 naturally occurring ones. The proteins immediately fold, assisted or unassisted, to form a distinct three-dimensional shape. The three-dimensional organization dictates the functions of proteins, which are the workhorses of the cell, performing all functions in a very well-orchestrated manner. Depending on time, type, and location of the cell, one gene can code for different variants of proteins, called isoforms, that can have different shapes and functions. As Francis Crick has said, “The ultimate aim of biology is in fact to explain all biology in terms of physics and chemistry. Eventually, one may hope to have the whole of biology ‘explained’ in terms of the level below it, and so on right down to the atomic level”. In order to understand the function of proteins at the atomic level, it is absolutely essential to see their three-dimensional structures at atomic resolution. X-ray crystallography, NMR spectroscopy, X-ray-free electron laser (XFEL), and single-particle Cryo-Electron Microscopy are used to determine the atomic-resolution three-dimensional structures of proteins.
Our group has been working on a class of RNA-binding protein domains known as RNA Recognition Motif (RRM), or Ribonucleoprotein domain (RNP), which is found to be the most abundant nucleic acid-binding domain in higher vertebrates. In humans, about 2% of the genome codes for RRM, and more than 500 RRM-containing proteins have been annotated. They are found in single copies, multiple copies, or in conjunction with other domains in the same protein. Studies show that RRM domains not only recognize nucleic acid but are also engaged in protein-protein interactions and protein-lipid interactions, owing to their structural plasticity. RRMs typically have about 90 amino acids with a representative topology of β1-α1-β2-β3-α2-β4, wherein the four-stranded β-sheets are packed against the two α-helices. There have been several examples where the length of loops, α-helix, and β-sheet vary, and additional secondary structured elements at RRM extremities are well conserved. These are crucial for interaction, allowing longer RNA recognition. In our previous study, we discovered a novel mode of RNA interaction where an extended α1β2 loop of human TAF-15 protein recognised a stem-loop RNA.
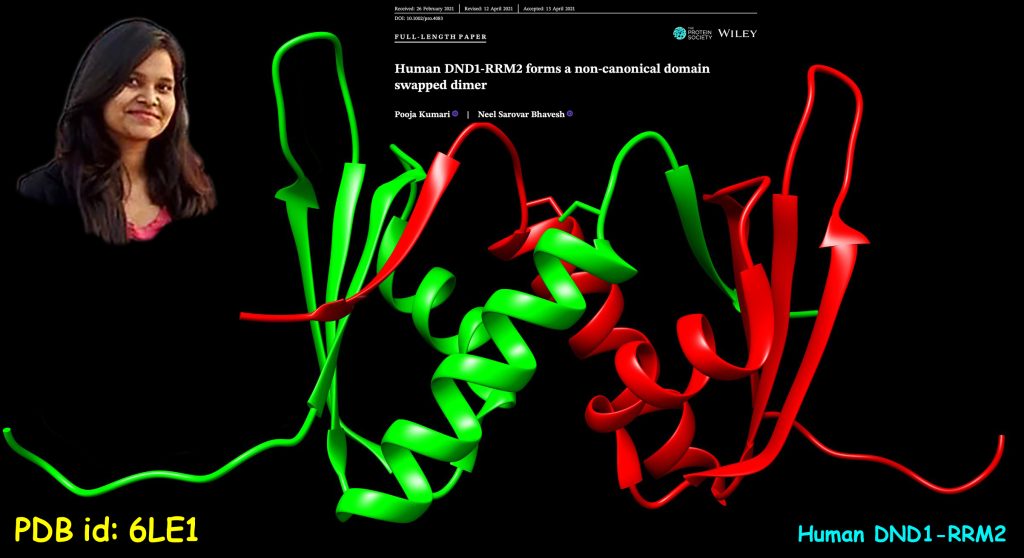
Due to its unique amino acid composition, we started working on human DND1 (Dead end protein homolog 1), also known as DND MicroRNA-Mediated Repression Inhibitor 1. DND1 is an RNA-binding protein containing two RRMs, RRM1 and RRM2 domains, in tandem, and a double-stranded RNA-binding domain at the C-terminal, separated by 40 40-residue flexible linker. In humans, reports of dysregulation at DND1 or mutation in the gene have been associated with testicular cancer and tongue squamous cell carcinoma. We have determined the atomic-resolution crystal structure of DND1-RRM2 and observed a novel domain-swapped dimer formation, like one seen in HIV-1 protease. We validated the domain-swapped dimer formation in solution using nOe and relaxation data from NMR spectroscopy. Ours is the first report of domain-swapped dimer formation in any RRM, and it also points to the limitations faced by structure prediction tools. In conclusion, there is no substitute for experimentally determined structure if we have to appreciate protein diversity.
जीवन की कार्यात्मक इकाई कोशिका अपने भीतर जीवन की संहिता को चार रसायनों, ए, जी, सी और टी, के विभिन्न संयोजनों से बने डी.एन.ए. नामक लंबी शृंखला में संग्रहित रखती है। डी.एन.ए. के विशिष्ट हिस्सों को जीन या संहिता क्षेत्र कहा जाता है और एक कोशिका में कई जीन होते हैं। ये जीन एम-आर.एन.ए. नामक एक संदेशवाहक इकाई का उपयोग करके प्रोटीन बनाने का कार्य करते हैं। एम-आर.एन.ए. जीन के संहिता कूट को पढ़कर प्रोटीन को बनाते हैं। प्रोटीन कोशिका के अंदर राइबोसोम में एक शृंखला के रूप में जन्म लेते हैं, जिसके प्रत्येक मनका अमीनो एसिड होते हैं, जो प्राकृतिक रूप से पाए जाने २० अमीनो एसिड में से चुने जाते हैं। ततपस्चात प्रोटीन तुरंत ही अपने को मोड़कर एक त्रि-आयामी आकार को बना लेते हैं, जो वे स्वतः करते हैं अथवा अन्य घटकों की सहायता से। उनकी त्रि-आयामी संरचना ही प्रोटीन के कार्यों को निर्धारित करती है। प्रोटीन कोसिका के मुख्य कार्यवाहक हैं जो सभी कार्यों को सुनियोजित तरीके से करते हैं। समय, प्रकार और कोशिका में स्थान के आधार पर, एक ही जीन विभिन्न प्रकार के प्रोटीनों के लिए कूट कर सकती है, जिन्हें आइसोफॉर्म कहा जाता है, जिनके अलग-अलग आकार और कार्य हो सकते हैं। जैसा कि फ्रांसिस क्रिक ने कहा है; “जीव विज्ञान का मूल उद्देश्य वास्तव में भौतिकी और रसायन विज्ञान के संदर्भ में जीव विज्ञान की सम्पूर्ण व्याख्या करना है। अंतत: ऐसी उम्मीद की जा सकती है कि संपूर्ण जीव विज्ञान की “व्याख्या” आणविक स्तर या उससे अच्छी स्तर पर की जा सकी।” परमाणु स्तर पर प्रोटीन के कार्य को समझने के लिए उनकी त्रि-आयामी संरचनाओं को परमाणु-स्तर की प्रामाणिकता पर देखना नितांत आवश्यक है। एक्स-रे स्फटिकी, एन.एम.आर. वर्णक्रममापी, एक्स-रे मुक्त इलेक्ट्रॉन लेजर (एक्स.एफ.ई.एल) और एकल-कण अति-शीत इलेक्ट्रॉन सूक्ष्मदर्शी का उपयोग प्रोटीन के त्रि-आयामी संरचनाओं को परमाणु-स्तर की प्रामाणिकता पर निर्धारित करने के लिए किया जाता है।
हमारा समूह आर.एन.ए. के साथ सम्बंध बनाने वाले प्रोटीन इकाई के एक वर्ग पर काम कर रहा है जिसे आर.एन.ए. रिकॉग्निशन मोटिफ (आर.आर.एम.), या राइबोन्यूक्लियोप्रोटीन इकाई (आर.एन.पी.) के रूप में जाना जाता है, जो उच्च कशेरुकियों में सबसे प्रचुर मात्रा में पाया जाने वाला न्यूक्लिक एसिड से सम्बंध बनाने वाला प्रोटीन इकाई है। मनुष्यों में आर.आर.एम. के लिए लगभग २% जीनोम कोड करते हैं और अब तक ५०० से अधिक आर.आर.एम. युक्त प्रोटीन पाए गए हैं। वे एक ही प्रोटीन में एकल प्रति, एकाधिक प्रतियों या अन्य इकाई के संयोजन में पाए जाते हैं। अध्ययनों से पता चलता है कि आर.आर.एम. इकाई न केवल न्यूक्लिक एसिड को पहचानते हैं बल्कि अपनी संरचनात्मक ढलनशीलता के कारण वे प्रोटीन-प्रोटीन एवं प्रोटीन-वसा पारस्परिक सम्बन्धों में भी कारगर होते हैं। आर.आर.एम. में आमतौर पर लगभग ९० अमीनो एसिड होते हैं और उनकी प्रतिनिधिक सांस्थिति β१-α१-β२-β३-α२-β४ होती हैं, जिसमें ४ स्ट्रैंड से बने β-शीट २ और α-हेलिक्स पैक होते हैं। ऐसे कई उदाहरण हैं जहां छोरों की लंबाई, α-हेलिक्स और β-शीट भिन्न होती है और आर.आर.एम. छोरों पर अतिरिक्त माध्यमिक संरचित तत्व अच्छी तरह से संरक्षित होते हैं और लंबे आर.एन.ए. से सम्बंध स्थापित करने के लिए महत्वपूर्ण होते हैं । हमारे पिछले अध्ययन में हमने आर.एन.ए. से जुड़ने के एक नए तरीक़े की खोज की थी जिसमें मानव टी.ए.एफ-१५ प्रोटीन में स्थित एक विस्तारित α1-β2 लूप स्टेम-लूप आर.एन.ए. से सम्बंध स्थापित करने में सहायक होता है।
अपनी अमीनो एसिड संरचना के कारण हमने मानव डी.एन.डी.-१ (डेड एंड प्रोटीन सधर्मी १) पर काम करना शुरू किया, जिसे डी.एन.डी. माइक्रो आर.एन.ए.-मध्यस्थता दमन अवरोधक १ के रूप में भी जाना जाता है। डी.एन.डी.-१ आर.एन.ए. से सम्बंध स्थापित करने वाला एक प्रोटीन है जिसमें दो आर.आर.एम. इकाइयाँ, आर.आर.एम.-१, आर.आर.एम.-२, होते हैं। सी-किनारे पर एक द्वि-भंजी आर.एन.ए. से जुड़ने वाली इकाई होती है जिसके और दोनो आर.आर.एम. इकाइयों के मध्य ४० अमीनो एसिड अवशेषों वाला संयोजक होता है। मनुष्यों में, डी.एन.डी.-१ में विकृति या जीन में उत्परिवर्तन के कारण वृषण कैंसर, जीभ स्क्वैमस कोसिका कार्सिनोमा जैसी बीमारियाँ होती हैं। हमने डी.एन.डी.-१-आर.आर.एम.-२ की परमाणु-स्तर की संरचना का निर्धारण एक्स-रे स्फटिकी से किया है। हमने पाया कि इसकी संरचना भिन्न प्रकार की है जो पहले किसी भी आर.आर.एम. इकाई में नहीं देखी गयी थी। इसकी संरचना ने डी.एन.डी.-१-आर.आर.एम.-२ की दो इकाइयाँ एक दूसरे से जुड़के हुयी हैं जिसमें दोनो का कुछ हिस्सा एक दूसरे के भीतर चला गया है। इसकी समानता एच.आई.वी.-१ प्रोटीज़ की संरचना से की जा सकती हैं। हमने एन.एम.आर. वर्णक्रममापी से एन.ओ.ई. और विश्रांति आँकड़े का उपयोग करके इसकी पुष्टि की। किसी भी आर.आर.एम. में ‘डोमेन स्वैप्ड डिमर फॉर्मेशन’ की हमारी पहली रिपोर्ट है और यह संरचना की भविष्यवाणी करने वाली साधनों के समक्ष आने वाली सीमाओं की ओर इशारा करती है। अंत में, यदि हमें प्रोटीन में विविधता की सराहना करनी है तो प्रयोगात्मक रूप से निर्धारित संरचना का कोई विकल्प नहीं है।
References
- Kumari P* and Bhavesh NS* (2021) Human DND1-RRM2 forms a non-canonical domain swapped dimer. Protein Sci. 30, 1184-1195
- Structure co-ordinates: Protein Data Bank (PDB) accession numbers 6LE1.